本文是对论文 Attention Is All You Need 的中文精读与意译,不是逐字全文翻译。原论文由 Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser、Illia Polosukhin 撰写,最早提交于 2017 年 6 月 12 日,论文 DOI 为 10.48550/arXiv.1706.03762。
这篇论文解决了什么问题
在 Transformer 出现之前,主流的序列到序列模型通常基于 RNN、LSTM、GRU 或 CNN。它们已经能做机器翻译、摘要、语音识别等任务,但有两个明显瓶颈:
- 难以并行:RNN 必须按时间步顺序处理 token,第
t个状态依赖第t - 1个状态。序列越长,训练越慢。 - 长距离依赖成本高:当两个相关 token 距离很远时,信息要经过很多步传播,模型更难学到稳定关系。
论文的核心观点非常直接:序列建模不一定需要循环结构,也不一定需要卷积结构。只用注意力机制,也可以构建强大的编码器-解码器模型。
这个架构被命名为 Transformer。
论文的核心贡献
Transformer 的贡献可以压缩成几句话:
- 用 self-attention 替代 RNN/CNN 作为序列建模的核心算子。
- 通过 multi-head attention 让模型在多个子空间里并行关注不同关系。
- 使用 positional encoding 给模型注入 token 顺序信息。
- 在机器翻译任务上取得更好的 BLEU,同时训练速度更快。
今天的大语言模型大多仍然建立在这套思想之上。虽然后来的模型在规模、训练目标、归一化位置、激活函数、位置编码、注意力变体等方面做了大量改造,但“用注意力在 token 之间建立动态连接”这个底层思路没有变。
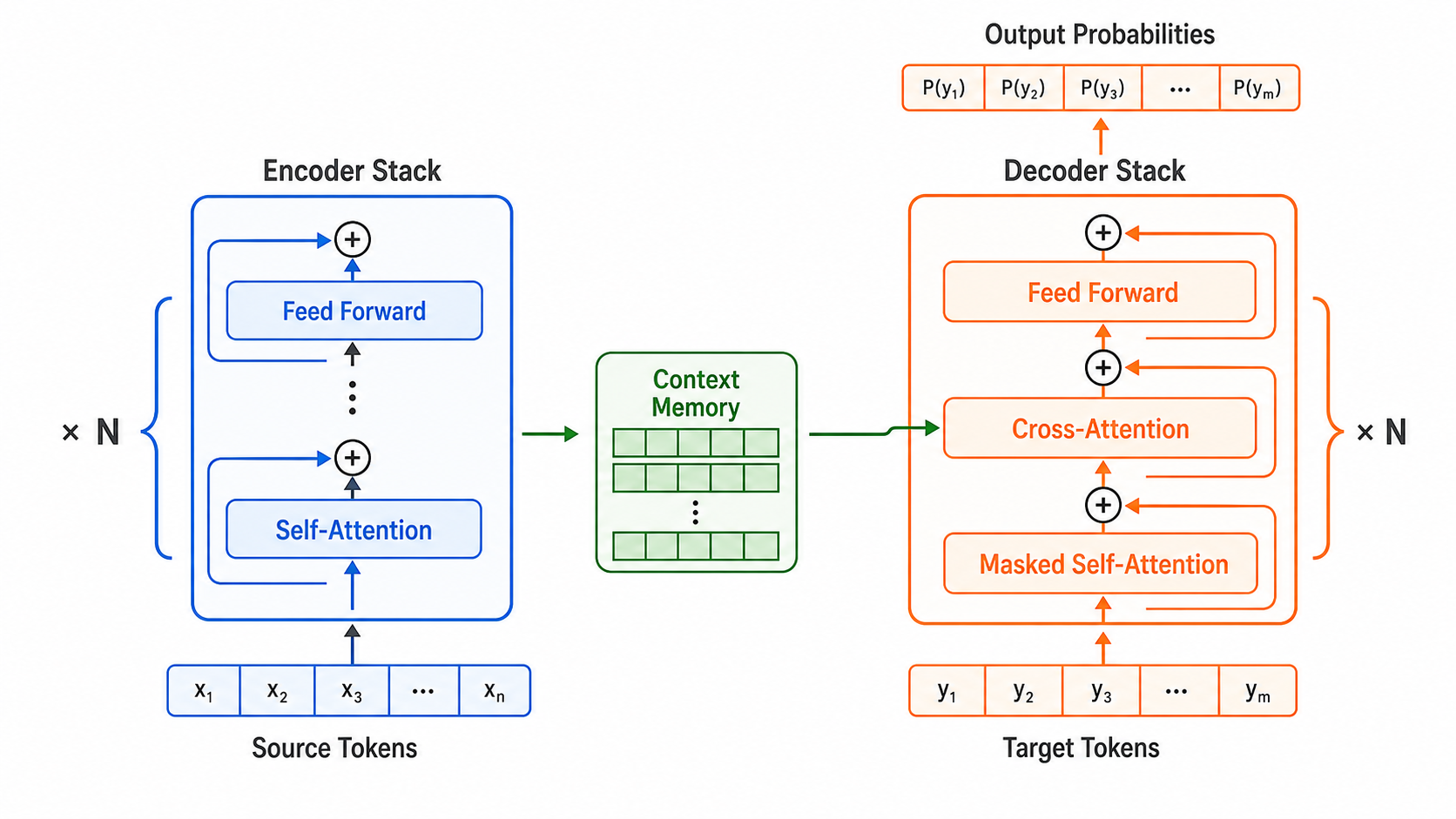
从 Encoder-Decoder 说起
论文仍然采用经典的 encoder-decoder 框架:
- Encoder:读取输入序列,把每个位置转换成上下文表示。
- Decoder:根据 encoder 输出和已经生成的 token,逐步预测下一个 token。
区别在于,Transformer 的 encoder 和 decoder 都不使用循环层。每一层主要由两类模块组成:
- multi-head attention
- position-wise feed-forward network
encoder 堆叠 6 层。decoder 也堆叠 6 层,但 decoder 额外包含一个 encoder-decoder attention,用于在生成目标序列时关注源序列。
Attention 的直觉
注意力机制可以理解为一次“按相关性加权的信息检索”。
给定一个当前位置的查询向量 Q,模型会拿它和所有候选位置的键向量 K 做相似度计算,再用 softmax 得到权重,最后对值向量 V 加权求和。这样当前位置就能从整段序列里取回和自己最相关的信息。
在机器翻译中,如果正在生成某个英文单词,decoder 可以通过 attention 找到源语言句子里最相关的词或短语。在 self-attention 中,每个 token 也可以观察同一个序列里的其他 token,从而建立句内关系。
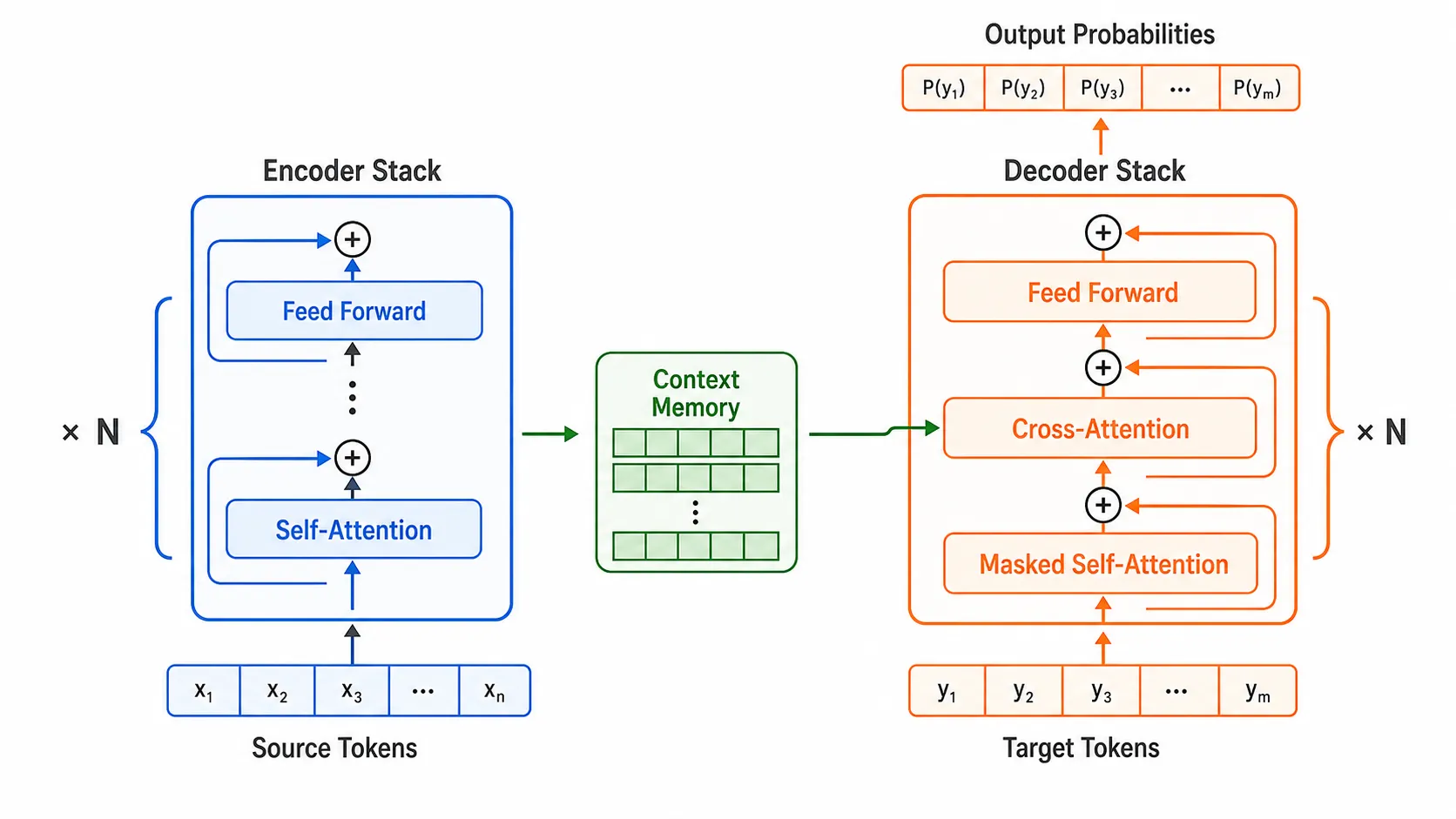
缩放点积注意力
论文使用的核心公式是:
Attention(Q, K, V) = softmax(QKT / sqrt(dk))V
这里:
Q是 query 矩阵K是 key 矩阵V是 value 矩阵dk是 key 的维度
为什么要除以 sqrt(dk)?
当向量维度变大时,点积结果的方差也会变大。过大的 logits 会让 softmax 进入饱和区,梯度变小,训练不稳定。缩放因子可以把数值拉回更合适的范围。
这个设计很朴素,但很关键。后来的大模型仍然沿用这一类 scaled dot-product attention。
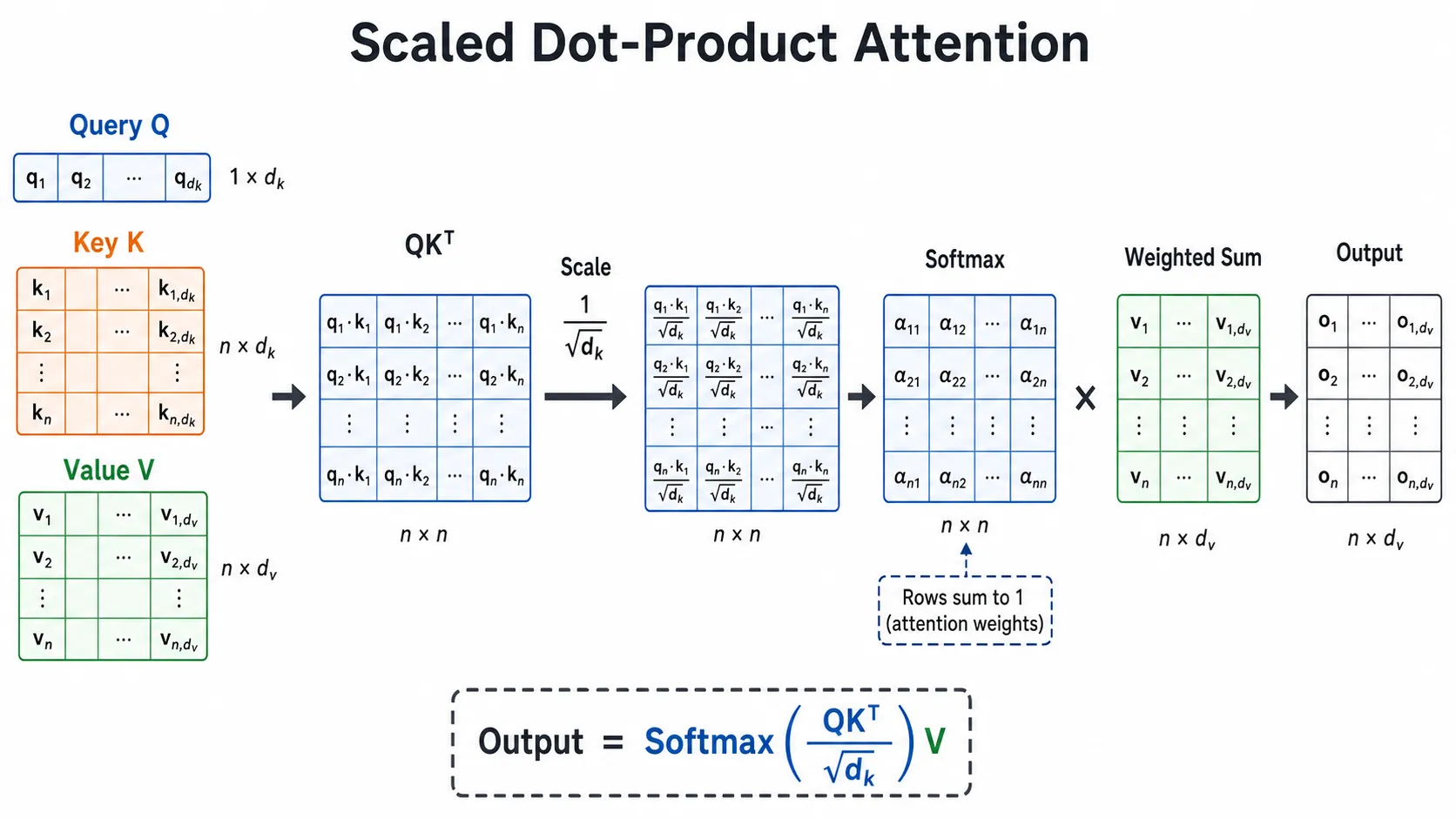
Multi-Head Attention
单个 attention 头只能在一个表示空间里计算相关性。论文提出 multi-head attention:先把 Q、K、V 投影到多个低维子空间,在每个子空间里独立做 attention,再把结果拼接起来。
可以把它理解成“多组观察角度”:
- 有的头关注局部短语结构。
- 有的头关注主谓宾关系。
- 有的头关注长距离依赖。
- 有的头关注对齐关系。
论文中的基础模型使用 8 个 attention head。每个 head 的维度较小,因此总计算量和单头高维 attention 接近,但表达能力更强。
Self-Attention 的优势
论文从三个角度比较 self-attention、RNN 和 CNN:
- 每层计算复杂度。
- 可并行程度。
- 长距离依赖路径长度。
self-attention 的最大优势是:任意两个 token 之间的路径长度是 1。一个位置可以直接关注另一个位置,不需要像 RNN 那样一步步传递,也不需要像 CNN 那样堆很多层扩大感受野。
这也是 Transformer 特别适合 GPU/TPU 的原因。训练时,同一层的所有位置可以并行计算,不再被时间步顺序锁住。
当然,self-attention 也有代价:标准 attention 对序列长度是平方复杂度。序列长度为 n 时,注意力矩阵大小是 n x n。这也是后来长上下文模型不断优化 attention 的原因之一。
为什么需要位置编码
如果只使用 attention,模型本身并不知道 token 的顺序。对于 self-attention 来说,输入 token 的集合如果没有位置信息,就很难区分“我喜欢你”和“你喜欢我”。
论文使用 sinusoidal positional encoding,把位置编号映射为一组正弦和余弦函数:
PE(pos, 2i) = sin(pos / 100002i / dmodel)
PE(pos, 2i + 1) = cos(pos / 100002i / dmodel)
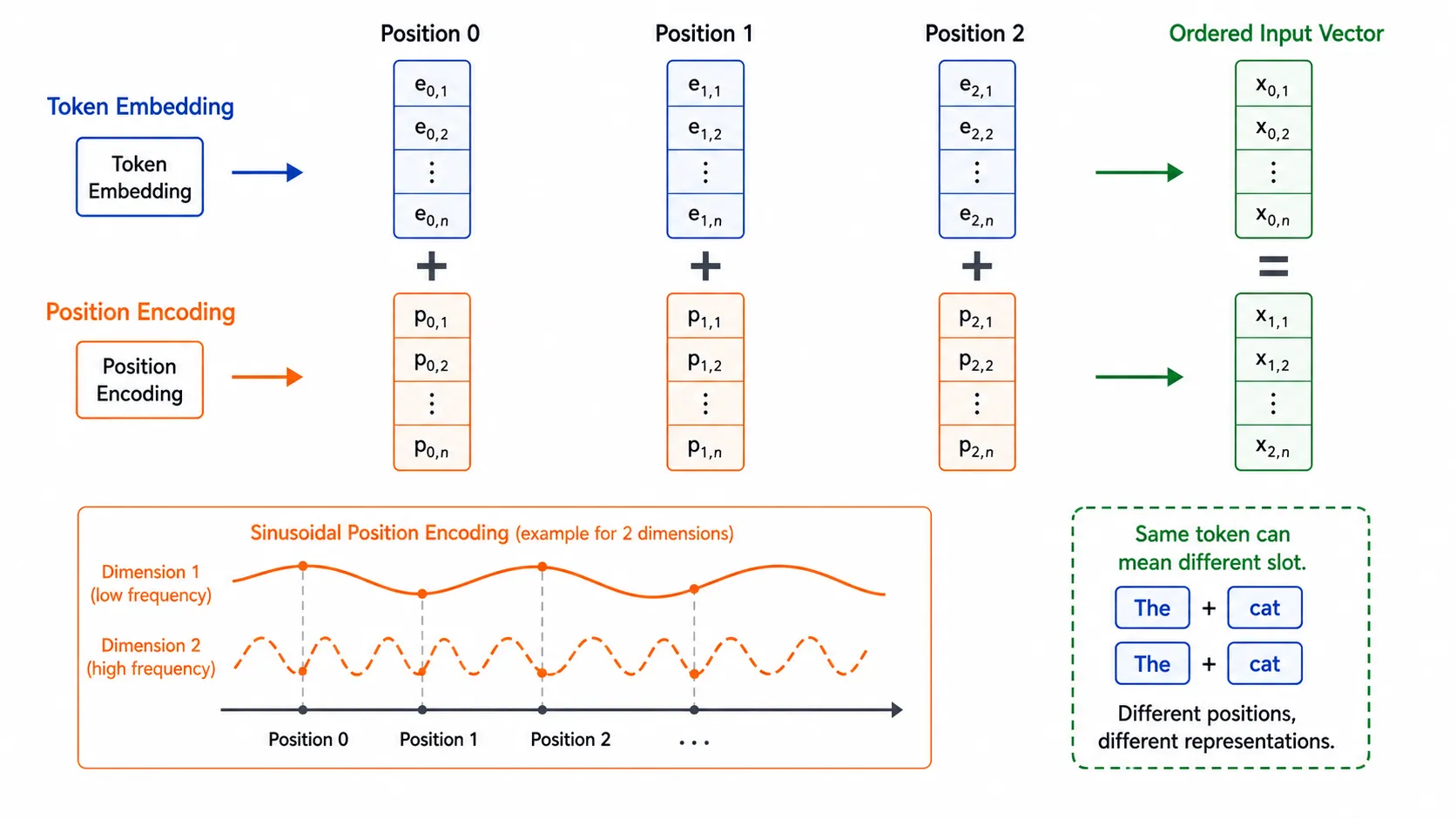
这样做有两个好处:
- 每个位置都有唯一的连续表示。
- 不同位置之间的相对偏移可以通过线性关系表达。
论文也尝试了 learned positional embeddings,结果相近。选择 sinusoidal 的一个理由是它可能更容易外推到训练时没见过的更长序列。
后来的模型继续围绕位置信息做了大量改进,比如 relative position、RoPE、ALiBi 等。
Encoder 层结构
每个 encoder layer 包含两个子层:
- multi-head self-attention
- position-wise feed-forward network
每个子层外面都有 residual connection 和 layer normalization。也就是说,每个子层实际形式接近:
LayerNorm(x + Sublayer(x))
论文中的 feed-forward network 是对每个位置独立应用的两层 MLP:
FFN(x) = max(0, xW1 + b1)W2 + b2
它不在不同 token 之间交换信息,token 间的信息交换主要发生在 attention 中。FFN 负责对每个位置的表示做非线性变换和特征组合。
Decoder 层结构
decoder layer 有三个子层:
- masked multi-head self-attention
- encoder-decoder attention
- position-wise feed-forward network
masked self-attention 用来防止模型在训练时看到未来 token。比如生成第 5 个 token 时,只能看第 1 到第 4 个 token,不能偷看答案里的第 6 个 token。
encoder-decoder attention 则让 decoder 的每个位置都能关注输入序列。这里 query 来自 decoder,key 和 value 来自 encoder 输出。
这套设计让 decoder 同时具备两种能力:
- 理解已经生成的目标语言上下文。
- 从源语言句子中检索相关信息。
训练细节
论文在 WMT 2014 英德翻译和英法翻译任务上评估 Transformer。几个值得注意的训练设计包括:
- 使用 Adam 优化器。
- 使用 warmup 学习率调度。
- 使用 label smoothing。
- 使用 dropout。
- 输入 embedding 和输出 softmax 前的权重共享。
学习率调度是论文里很有代表性的工程细节。训练开始时先 warmup,避免初期更新过大;之后按步数衰减。这个模式后来在训练大模型时也很常见。
label smoothing 则让模型不要过度相信 one-hot 标签,有助于提升泛化能力。
实验结果说明了什么
论文报告的结论是:Transformer 在机器翻译上同时获得了更高质量和更高训练效率。
在 WMT 2014 英德任务上,Transformer base 达到 27.3 BLEU,Transformer big 达到 28.4 BLEU。在 WMT 2014 英法任务上,Transformer big 达到 41.8 BLEU。
这些数字在当时很有说服力,因为模型不仅质量强,而且训练成本显著降低。论文强调的重点不是“模型更大所以更强”,而是“架构更适合并行训练,所以能更快得到强结果”。
为什么这篇论文影响这么大
Transformer 改变的不只是机器翻译。它提供了一种通用的 token 交互机制。
只要能把数据表示成 token 序列,就可以考虑用 Transformer:
- 文本:词、子词、字符。
- 图像:patch。
- 音频:帧或离散 token。
- 代码:语法片段或子词。
- 多模态:把不同模态映射到统一 token 空间。
BERT、GPT、T5、ViT 以及后来的大语言模型,都可以看作 Transformer 思想的延伸。它们的差别主要在训练目标、decoder-only/encoder-only/encoder-decoder 架构、数据规模和工程优化上。
需要注意的局限
Transformer 并不是没有代价。
首先,标准 self-attention 的显存和计算量随序列长度平方增长。短序列时这不是问题,但长上下文会迅速变贵。
其次,Transformer 缺少 RNN 那种天然的顺序归纳偏置。它依赖位置编码和数据学习顺序关系。这带来了灵活性,也意味着需要足够的数据和训练技巧。
最后,注意力权重并不总是可靠解释。虽然 attention map 看起来像模型在“关注”某些词,但不能简单把它等同于完整因果解释。
用一句话总结
《Attention Is All You Need》真正重要的地方在于:它把序列建模的核心从“按顺序递归处理”改成了“让所有 token 直接相互通信”。这个变化释放了并行训练能力,也给后来的大规模预训练模型铺平了道路。